使用模糊匹配器

也称为 Like Gambit,使用容错能力更强的语法定义规则。
模糊匹配器的功能
模糊匹配器的主要特点是支持设定多个句子,输入和句子进行匹配,根据阀值判定是否匹配。有默认阀值,Chatopera 机器人平台可以在机器人管理控制台设置页面,调整该阀值,也可以在每个匹配器上设定单独的阀值;该阀值的取值需要介于 0 和 1 之间,越高代表越严格的匹配,越相似。
基于模糊匹配器,匹配器的容错能力更强,调试更简单;但是模糊匹配器不考虑位置的因素,这一点与通配符匹配器较为不同。
模糊匹配器和通配符匹配器各有优劣,Chatopera 机器人平台开发者在看过不同的匹配器示例后,根据需要灵活选择。
接下来介绍模糊匹配器的详细使用。
模糊匹配器的语法
形式 1
+ ${threshold}{句子1|句子2|...|句子N}
- 回复
句子可以设定 1 或多个,多个句子时使用"|"进行分隔。threshold 的取值范围是 (0,1)。
比如:
+ ${0.7}{商场几点开门|商场营业时间}
- 营业时间:早上八点半至晚上十一点
形式 2
+ ${句子1|句子2|...|句子N}
- 回复
比如:
+ ${商场几点开门|商场营业时间}
- 营业时间:早上八点半至晚上十一点
在这种形式下,省略了形式 1 里的阀值 threshold,那么在计算输入和句子1,...,句子N 的是否匹配时,使用的阀值是机器人控制台【设置页面】设定的值【多轮对话模糊匹配阀值】,默认为 0.8。
匹配器及回复复用
模糊匹配器受机器人记忆模型限制,如果需要在一个记忆周期内一直生效,可以使用 {keep} 标记,比如:
+ ${商场几点开门|商场营业时间}
- {keep} 营业时间:早上八点半至晚上十一点
详细介绍,参考文档。
使用调试
对于一条模糊匹配器规则,究竟要适应多少种问法?容错是保守一点,还是要非常灵活?这需要在调试机器人时,Chatopera 机器人平台用户,自行判断。在多轮对话设计器内,可以增加模糊匹配器里的句子,或者适当的调节阀值 threshold。
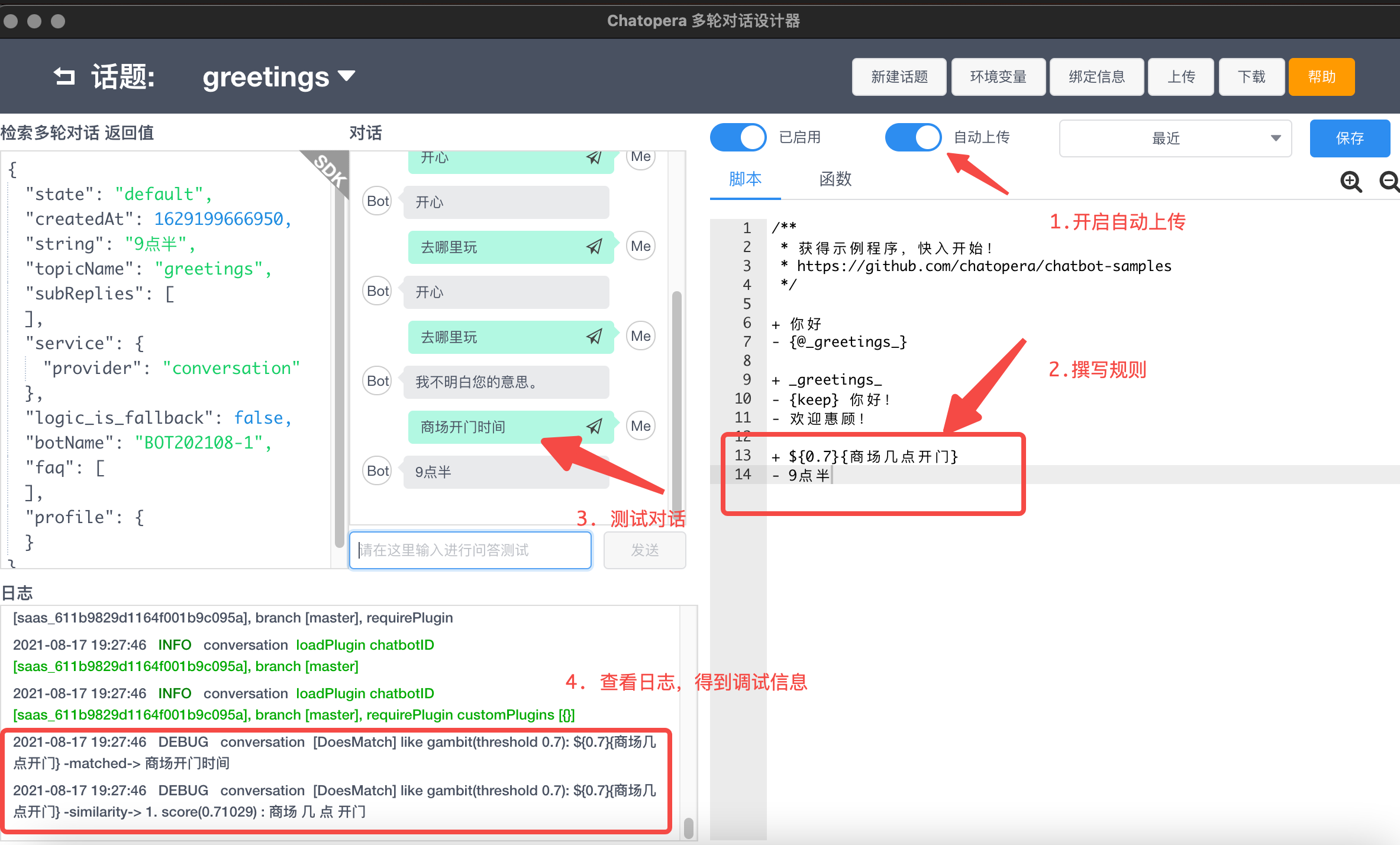
调试过程
1)开启自动上传;
2)撰写模糊匹配规则,设定答案;
3)保存;
4)在对话中,发送测试文本;
5)查看日志,得到匹配调试信息。
如下图:
调试信息
关于模糊匹配器在调试时,得到的调试信息,进一步介绍。
每个模糊匹配器,都会和输入进行比较,计算相似度,打印的日志类似:
2021-08-18 13:52:52 DEBUG conversation [DoesMatch] like gambit(threshold 0.8): ${商场几点开门} -similarity-> 1. score(1) : 商场 几 点 开门
其中,DoesMatch 是服务端计算该相似度的函数名,like gambit(threshold) 表示这个匹配器是模糊匹配,并输出本次的阀值,后面就是匹配器内容, -similarity-> 后的输出是每个句子和输入内容的相似度,score()内就是相似度,分数后面是句子的分词结果;多个句子时,使用 “|” 分隔。
比如:
2021-08-18 13:57:18 DEBUG conversation [DoesMatch] like gambit(threshold 0.8): ${商场几点开门|商场开门时间} -similarity-> 1. score(1) : 商场 几 点 开门 | 2. score(0.71029) : 商场 开门 时间
以上句子之间增加了序号,按照分数由大到小进行排列。
如果模糊匹配器的一个句子与输入之间相似度大于阀值,那么就判定为匹配,输出日志类似如下:
2021-08-18 13:57:18 DEBUG conversation [DoesMatch] like gambit(threshold 0.8): ${商场几点开门|商场开门时间} -matched-> 商场几点开门
模糊匹配器取值
如果匹配上模糊匹配器,回复的函数中,可以获得到哪些信息,进一步的让回复内容更加智能?
模糊匹配器上,函数中利用输入的自然语言处理信息办法:使用 this.message 内包含的信息进行分析。
假如有这样的脚本和函数:
/**
* 模糊匹配器示例脚本
*/
+ ${商场几点开门|商场开门时间}
- ^getOpenTime()
exports.getOpenTime = async function() {
debug("getOpenTime words %j", this.message.words) // this.message.words 是 JSONArray
debug("getOpenTime tags %j", this.message.tags) // this.message.tags 是 JSONArray
return "九点半"
}
那么,就可以在 this.message.words 中得到分词的信息,在 this.message.tags 得到相对应位置的词性。
比如,如果输入是 “商场的开门时间”,那么相应的 words 和 tags 如下:
getOpenTime words: ["商场","的","开门","时间"]
getOpenTime tags: ["nis","ude1","vi","n"]
所以,"商场"的词性是"nis","的"的词性是"ude1"。那么,"nis" 和 "ude1" 又代表什么呢?它们是词性标识。
在 Chatopera 机器人平台,不同语言使用词性标识因为语言本身的原因,不是很一致。
| 语言 | 词性标注集 |
|---|---|
中文(简体中文 zh_CN,繁体中文 zh_TW) |
文档 |
| 英文 / en_US / Enlgish | 文档 |
| 日语 / Japanese | 文档 |
得到匹配信息,再结合 Chatopera 机器人平台内其它的内置函数库,可以实现更为强大的对话能力!
通过提供不同形式的匹配器,适合智能对话机器人开发者在不同场景下因地制宜的选择构建规则的方法。